Event Sourcing and Microservices – Unix Style
The title is a bit tongue in cheek. The subtitle would be something like How looking at ideas behind architectural patterns can yield good solutions even when common implementations would be overly complex.
I struggled with this article, and it’s because it tries to make two points at the same time1 Which ironically means it has low cohesion and high coupling.:
- It tries to be a rant against overcomplicating implementations. This will be covered briefly, and then I hope a more complete treatment can be a separate article.
- It also tries to be an example of how software following the Unix philosophy doesn’t have to be hard to write. In fact, the design can evolve in that direction almost accidentally.
Write programs that do one thing and do it well. Write programs to work together.
This is easy if you’re not afraid of keeping things simple.
Don’t confuse shiny tools with core ideas
The title promises event sourcing and microservices. The article will deliver on them in spirit, but not perhaps in the technical detail you would expect. We are going to see 78 lines of code, so it will seem a bit silly to talk about architectural patterns. If you want, you can imagine this to be a larger, more complicated system. But the truth is good ideas help even small systems like this one.
The two ideas to rule them all are cohesion and coupling. Many of the other good practises we find in software engineering are really instances or variations of high cohesion and/or low coupling.2 Single responsibility, dry, wet, interface segregation, structured programming, pure functional programming, cqrs, microservices, message passing, and the list goes on. This is not an accident, it comes down to what makes systems complex in general. If we can reason about components in isolation, the system is less complex, and less complex systems are much easier to work with.
The code we’ll see makes up the following system.
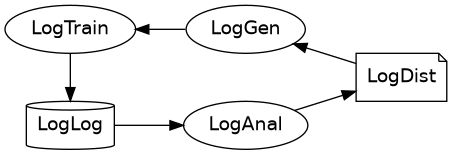
If we wrap this system in buzzwords, we have
- The three services, LogTrain, LogAnal, and LogGen have a single responsibility and can be deployed independently as long as they continue to conform to the protocol the other services expect. They perform their aggregate functionality by talking to each other.
- LogLog is an append-only event log that serves as the authoritative source for the state of the system. It is updated live by LogTrain every time the user makes a guess, and any other application can read from it to find out what the state of the application is and compute derived state (e.g. LogDist).
One could imagine implementing this with message buses and containerised web API server applications orchestrated by Kubernetes. I believe that would be confusing the tools with the ideas. It’s easy to lose sight of the core ideas:
- Maintain high cohesion in components by having separate components for separate responsibilities.
- Maintain low coupling by isolating component runtimes and having them communicate asynchronously.
When you back out of the shiny tools and return to the core ideas, it’s easy to see there might a simpler way to implement the system: regular scripts executed at the command line, that communicate by writing and reading plain files. Unless you really need some of the promises made by event buses and Kubernetes (which in many cases you don’t) you can get the same benefits with plain command line scripts and text files. The advanced tools serve their purpose in specific contexts, but they should not be mistaken for embodiments of the core ideas.
I would argue that even if you think you need event buses and Kubernetes, try implementing the mvp with command line scripts and text files. You might be surprised how quick you can go, how far that will take you, and once you have something working you can optimise for edge cases.
Accidentally following the Unix philosophy
Onwards to the example. I mentioned previously that it would be nice with a script to practise mentally taking the logarithms of random numbers. 3 I have long been looking for a way to create these kinds of small one-off applications for my phone to use on the go, but without having to learn all of Android development. It just struck me that Termux doesn’t just run ssh; it can also run any script I care to write. I can even install nvim on it to edit the scripts and fix bugs in them. The exact details of these scripts aren’t important, but they provide a concrete example we can discuss.
You have already seen the system diagram above, but we can look at it again with the real filenames we’ll see in this section, and the real communication mechanisms.
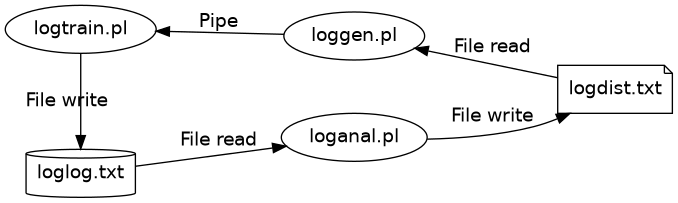
The design didn’t start out looking like that. It grew there organically, as I realised there were opportunities for cheap wins.
A guessing loop is actually all we need
I wrote logtrain.pl on my phone when I had some waiting time to kill. Even
with the awkward keyboard, it probably took less than 20 minutes in
total.4 On the phone, I ended up using a lot of single-character variable
names and didn’t write many comments. I have fixed some of that for the code in
this article. While writing I also noticed some inconsistencies and small latent
bugs that are fixed now. I remain convinced that self-reviewing code gets you at
least 20 % of the value of having a trusted colleague review code.
I won’t dwell on this first version because it’s simple enough to be an introductory tutorial to a scripting language: generate a random number, ask the user for the logarithm of it, then print what the actual logarithm was so the user can check their result, then repeat until eof.5 One thing of note, perhaps, is that this script generates a random value for \(\log{x}\) and then displays \(10^{\log{x}}\) to the user. The reason for doing that way is to give the user a uniform distribution of logarithms to guess from. Generating \(10^x\) directly (which would be the natural thing to do) would have biased the logarithms heavily upwards.
use v5.16; use warnings; use strict; sub guess_round { my $n = 1/100 * int (10**(rand 6)); # Format with appropriate number of decimals for number size. my $fmt = $n > 10 ? "%.0f" : ($n > 1 ? "%.1f" : "%.2f"); printf "log $fmt ?\n", $n; # Read until EOF or valid guess. my $guess; while ($guess = <STDIN>) { last if $guess =~ /[0-9.]/; say "Invalid guess." } return unless defined $guess; # Print actual logarithm for self-checking. my $actual = log($n) / log(10); printf "actual: %.3f\n\n", $actual; # Indicate to outer loop that we want to go on. return 1; } while (guess_round) {}
At this point, this is the only component in the system and it doesn’t talk to anything else. It interacts with the user like this:
$ perl logtrain.pl log 535 ? 2.7 actual: 2.728 log 2.8 ? 0.46 actual: 0.441 log 586 ? 2.8 actual: 2.768 log 1344 ? 3.15 actual: 3.128 log 2.0 ? ...
If looking for a place to stop programming and start practising logarithms, this is a great place to stop. The script has every feature it needs.
Performance logging makes it quantitative
But! There should be something bothering you: we are trying to improve something (our mental logarithm skills) but we don’t have a quantitative measure of whether improvement is happening at all. Any improvement effort should involve trying to measure the improvement so we can know if we are doing something useful or wasting our time.
This means inserting some logging to logtrain.pl. One way to do it is to
change guess_round to return the tuple of ($actual, $guess - $actual), and
then change the main game loop to include the logging:
open(my $log, ">> :encoding(UTF-8)", "loglog.txt"); say $log "NEW SESSION"; while (my ($actual, $difference) = guess_round) { printf $log "%.5f %.5f\n", $actual, $difference; $log->flush; }
This will generate a log file that looks like
$ cat loglog.txt NEW SESSION 2.72818 -0.02818 0.44091 0.01909 2.76784 0.03216 0.29667 0.00333 NEW SESSION -1.15490 -0.04510 2.01494 -0.01494
At this point, the system looks like

Printing the new session markers every time the script starts up is a crude way to track progress over time. By picking up those markers we can write an ugly oneliner to summarise performance over time:
$ cat loglog.txt | perl -lane 'if (/NEW SESSION/) { $n and print $ssq/$n; $ssq=0; $n=0; } else { $ssq+=$F[1]**2; $n++; }'
0.00053487022
0.82406979478
0.82982874455
This prints out the mean sum of squared errors for each session. If that number doesn’t start to go down with increased practise, we should be looking at some other way to get better.
Okay, great, now we can stop programming and start practising, right?
Analytics can be extracted from the log
Yes, except the log file also contains a key to diagnosing our performance. We are measuring accuracy as the squared error, which means to reduce the error efficiently, we should focus on the biggest problems first.6 Kahneman talks about this in Noise; any time you’re optimising a squared loss function, you get more from reducing a big error by a little than a small error by much. This makes sense since mound-shaped loss functions in general are synonyms for “don’t sweat the little things” thanks to their flatness around the optimum. I’m sure I’m better at some ranges of logarithms and worse at others. Where do I make the biggest errors? The log file knows, and we can extract that information by constructing a histogram for the various logarithm ranges of interest.7 Since the non-fractional part of a base-ten logarithm is equal to the number of digits up to the units position, we ignore slips of the finger involving those, and focus on the fractions which are the difficult bit.
This is performed by loganal.pl.
use v5.16; use warnings; use strict; use List::Util qw( max ); my $buckets = 10; my @histogram; open(my $log, "< :encoding(UTF-8)", "loglog.txt"); while (<$log>) { next if /NEW SESSION/; # This analyses only the fractional part, leaving errors of magnitude # estimation a problem for someone else. /^-?\d+\.(\d+) -?\d+\.(\d+)$/ or die "Unrecognised format $_"; my $b = int($1/10**5 * $buckets); my $diff = abs ($2/10**5); $diff = 1-$diff if $diff > 0.5; # Measure squared error to penalise large mistakes more heavily. $histogram[$b]{ssq} += $diff**2; $histogram[$b]{n}++; } # Measure skill as the mean of the squared error for each bucket. my @mean_error; for my $b (0..$buckets-1) { # If this bucket has not been practised at all yet, give it a huge mean_error. defined($histogram[$b]) or $mean_error[$b] = 1, next; $mean_error[$b] = $histogram[$b]{ssq} / $histogram[$b]{n}; } my $max = max @mean_error; # Write histogram to file. open(my $dist, "> :encoding(UTF-8)", "logdist.txt"); for my $b (0..$buckets-1) { my $lower_bound = $b/$buckets; my $upper_bound = $lower_bound + 1/$buckets; my $bar_length = 30/$max * $mean_error[$b]; printf $dist "%.2f--%.2f %.10f %s\n", $lower_bound, $upper_bound, $mean_error[$b], '-' x $bar_length; }
By the way, the histogram is a seriously undervalued data structure. It’s the
way to store data approximately when order doesn’t matter, but it’s missing from
virtually every standard library8 Yes, even Python. The Counter class can
only deal with categorical data, not floats.. Fortunately a crude version is
easy to make on your own. If you want something for production use, I warmly
recommend HdrHistogram.
This script will create a new file logdist.txt which contains something like
$ perl loganal.pl && cat logdist.txt 0.00--0.10 0.0001205906 -- 0.10--0.20 0.0005869017 --------- 0.20--0.30 0.0003543788 ----- 0.30--0.40 0.0003568321 ----- 0.40--0.50 0.0017917269 ------------------------------ 0.50--0.60 0.0005234944 -------- 0.60--0.70 0.0003712724 ------ 0.70--0.80 0.0005121528 -------- 0.80--0.90 0.0001640814 -- 0.90--1.00 0.0000484416
Great. We now know that I’m not very good at the 0.4–0.5 range, which corresponds to taking the log of numbers roughly between 2.5 and 3. This may be in part because I’ve memorised \(\log{3} \approx 0.5\) when it’s actually closer to \(0.47\). We learned what we wanted!
The system is now
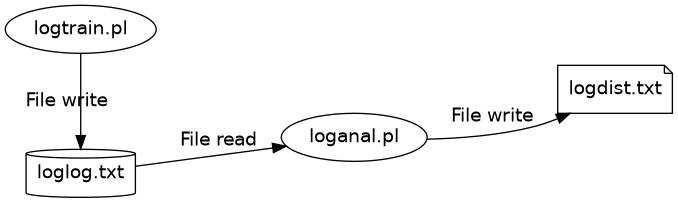
Again, good place to stop programming and continue practising.
Focused practise can be derived from analytics
But look at what loganal.pl just produced. It made something that, if you
squint, sort of looks like a probability density that predicts how bad I am at
different logarithms. If we could generate logarithms with sort of that
density we could have focused practise mainly on the numbers we’re bad at.
This is what loggen.pl does. First it reads the pretend density from
logdist.txt and converts it to a cumulative probability distribution. Then it
enters an infinite loop that draws random numbers from that cdf.
use v5.16; use strict; use warnings; my @x = (0); my @cdf = (0); open(my $dist, "< :encoding(UTF-8)", "logdist.txt"); while (<$dist>) { /^\d\.\d+--(\d\.\d+) (\d.\d+)/ or die "Unrecognised format $_"; # For each histogram bucket... push @x, $1; # ...create the corresponding cumulative probability. push @cdf, $cdf[$#cdf] + $2; } # Normalise distribution so it sums to 1. $_ /= $cdf[$#cdf] for @cdf; while (1) { my $r = rand(); for my $i (1..$#x) { next if $cdf[$i] < $r; say (rand ($x[$i] - $x[$i-1]) + $x[$i-1]); last; } }
The first few lines of its output might look like
$ perl loggen.pl | head -n 5 0.715224078842172 0.447936494098662 0.248107602352682 0.042294572367708 0.450150342244956
Now we have a system where the new part is neat, but it doesn’t really … do anything.
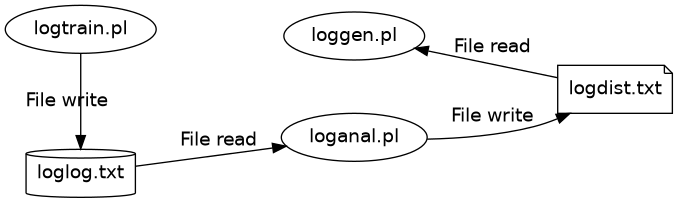
The last step is modifying logtrain.pl to pipe numbers from loggen.pl instead of
generate its own. The changed parts are
... sub guess_round ($) { # Get the fraction of log(n) from the random number source. my $fraction = shift; # Pick a random integer part for log(n). my $y = int(rand(6)) + $fraction; # Compute 10^log(n). my $n = 1/100 * int (10**$y); ... } # Pipe appropriately distributed random numbers to guess_round. open(my $generator, "-| :encoding(UTF-8)", "perl", "loggen.pl"); ... while (my ($actual, $difference) = guess_round(<$generator>)) { ... }
Producing the final system
This is the place I stopped programming. There are other ways we can still
improve this9 One thing that irks me is that loggen.pl depends on
logdist.txt existing, which in turn depends on loglog.txt, meaning to cold
start these scripts, we need to create an empty log file first and generate a
uniform distribution from it. It would be nice if loggen.pl could generate
uniformly distributed logarithms on its own when it doesn’t have a distribution
to go by., but now is a good place to talk about architectural patterns instead.
Loose coupling and high cohesion wins the game
This system is a total of 78 lines of code. We could have designed it as a fully integrated monolith. However, that would cause decreased cohesion: any time there’s a bug, we have to locate it in 78 lines of code, rather than an average 25 we have with the components decoupled. Besides, we would have 78 lines of code running whenever the program runs, which gives a greater surface area for errors.
Also note how naturally we could extend the system with new functionality when it was uncoupled this way? We think of an idea and we write a new script that reads one file and writes another. Scripts are the functions of Unix – if we work this way, we work with the system, rather than against it. At a performance penalty, yes, but is that really a problem in this case?
If we built it as a monolith, it might not have been as natural to log events. One should log events; they are the atoms of a process. Events are immutable. Events make no assumptions about how the information will be used, and this is why events decouple components.
There’s one complaint one can make about this highly decoupled design:
loggen.pl doesn’t use information from the latest guesses to influence the
distribution. It reads the logdist.txt at startup and then reuses that
information for as long as it runs. If the system was made as a monolith, it
would probably be tempting to update the distribution live. We can do that also
with the separate scripts, but there’s a reason we don’t: it temporally couples
the analytics code with the generation code. As the system is written now, there
is no requirement that analytics run in parallel with generation. We can produce
logdist.txt however we want at any time we want, and loggen.pl would be none
the wiser. This is a property that should not be surrendered easily! Is the
freshest information really worth it?