On Competing with C Using Haskell
Mark Karpov wrote in his article on Migrating text metrics to pure Haskell how he originally did foreign calls out to C for many of the functions in his text metric package, but now ported them to Haskell when he learned that Haskell can give you performance comparable to C.
The first example of a function ported to Haskell from C already struck me as odd. It measures the Hamming distance (i.e. "if you line these two strings up above and below each other, at how many positions are the corresponding characters different?") of short strings (largest length Karpov tests is 160 characters). You can see it here:
let
len = TU.lengthWord16 a
go !na !nb !r =
let
!(TU.Iter cha da) = TU.iter a na
!(TU.Iter chb db) = TU.iter b nb
in
if | na == len -> r
| cha /= chb -> go (na + da) (nb + db) (r + 1)
| otherwise -> go (na + da) (nb + db) r
in
go 0 0 0The target implementation (which is what I'll call the code above) uses some sort of unsafe iterators to loop through the available characters, and compare them one by one. The code looks cumbersome. But apparently it has performance very similar to C, so it's not bad by any stretch of the imagination. (You'll notice that I have elided the length check mentioned by the original author – I'll get back to that!)
I got curious. How well does the compiler optimise various ways of counting in how many places two strings differ from each other?
Disclaimer: none of the implementations I present here are the fruit of extensive searches for optimal code. I just try a few variations that I think, based on intuition, will be fast, and then I benchmark and pick the best and most readable code.
What Does "C-like performance" Mean?
This is not a marketing article. I'm investigating how well the Haskell compiler can optimise stuff; I'm not trying to compare languages. I do think Haskell is great, as regular readers of this blog know, but I don't want to pretend it's something it's not.
Calling out to a C function from Haskell code carries some overhead. The primary cost is that the Haskell compiler can't inline and optimise across the language boundary; when the Haskell compiler sees a function written in C, it simply treats that as a black box. It sets up according to the correct calling convention, and then dispatches control entirely over to the code compiled from C.
The C function will be optimised – but only in isolation, not in conjunction with the code surrounding the call. This means that when a Haskell and a C function have equivalent performance under no opimisations, once you apply optimisations the Haskell code will be faster, because it can be inlined and optimised with regards to its surroundings.
So when people say "C-like performance" in this sort of context, what they really mean is "the performance if we choose to make a foreign call to a function written in C instead of writing the same function in Haskell".
Streaming Abstraction: Conduit
runConduitPure
( yieldMany (Text.zip a b)
.| lengthIfC (uncurry (/=))
)There are a few Haskell libraries that abstract over streams of data. The pipes library is popular, and so is the conduit library. I'm more familiar with conduit, so that's what I tend to reach for when I have a problem involving streaming data. Both conduit and pipes promise performance, and tend to do very well when the problem is of a larger scale (say, a web server).
This is a very small scale problem. It's essentially one, tight little loop. The most complicated thing it does is decode 16-bit values into characters, which is nowhere near web scale I/O based streaming, so it's not obvious streaming abstractions will perform well here.
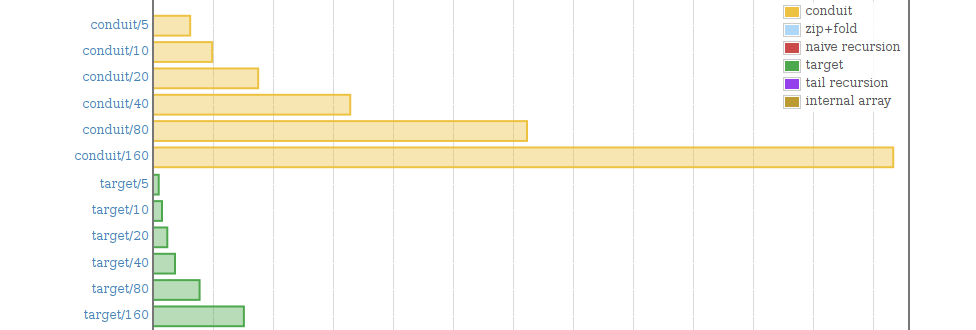
Clearly, streaming abstractions present with the overhead we associate with abstractions in general. We're still talking about an overhead of 5 µs for 160 characters (about a sixth of a second for 10 megabytes), but it's significant compared to the target.
This tells me that for simple problems (i.e. not building a web server), streaming abstractions should not be used for their performance. They might, however, still be valuable for their resource usage guarantees. One of the stronger benefits of streaming abstractions is that they often promise constant memory usage (where such a thing makes sense, of course).
Compositional, Functional Solution: Zip+Fold
foldl'
(\distance (cha, chb) ->
if cha /= chb then
distance + 1
else
distance
) 0 (Text.zip a b)This is another good default option for streaming data, and what I would have reached for before I got comfortable with conduit. A strict left fold is then essentially "a loop for counting things from a collection", where the word "counting" is used pretty loosely*. The left fold expects to go through all elements in the collection and update some sort of accumulator based on each one. Here, we count each matching corresponding character pair.
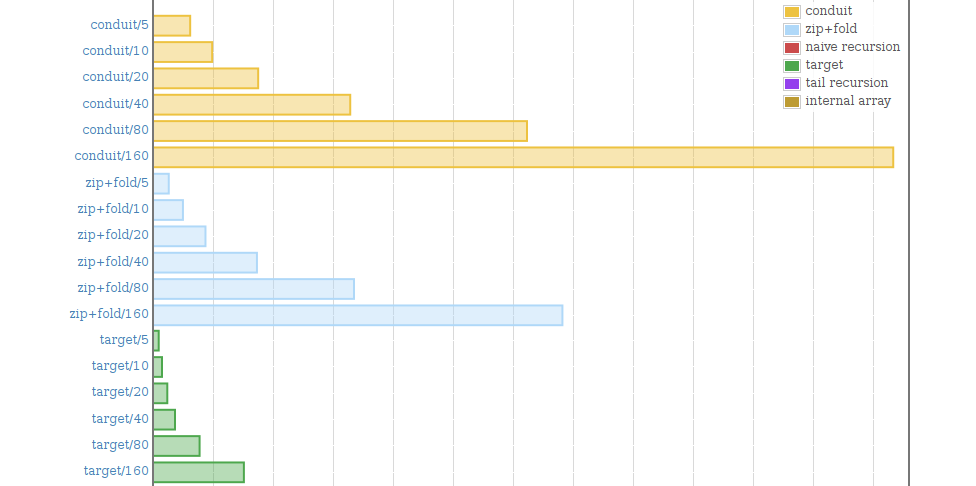
And it's decent! It's nowhere near the target yet, but it is better than the streaming abstraction, and almost halfway to the target (which promises C-like performance). I can excuse this being slow, because this is reasonably high-level code, which means it's going to be easy to maintain compared to the target. And on 10 megabytes of data, we're only spending an additional tenth of a second in computer time!
Interlude: What Is Reasonable Expectation?
I've been throwing around a lot of numbers. Ten megabytes here, 5 µs there, half of this there. Let's get some perspective.
According to the interactive diagram of Latency Numbers Every Programmer Should Know, a branch mispredict on my machine takes about 3 ns. Reading a megabyte from memory is near 13 µs. If we reach into our asses and pull out a number, we can pretend that the input strings are such that branch mispredicts happen every ten iterations. Then we can estimate the time required to find the Hamming distance of ten megabytes to be at least 400 µs (= 10× reading a megabyte + a million branch mispredicts / 10).
So a really good implementation should be able to produce an answer somewhere in that order of magnitude, i.e. somewhere in the 0.4–4 ms range. I just tested with a pure C algorithm which does it in 8 ms when optimised only by compiler, not by hand. Optimising it by hand, I'm sure one could get it down to under 4 ms. That's pretty cool! We can estimate optimal performance targets by taking the largest latency numbers involved and doing some multiplication. Fermi would have been proud.
We're not quite there yet with our own Haskell code, though, but the target implementation does it in about a hair under 30 ms.
Explicit Recursion
naiveRec a b =
if Text.null t then
0
else if Text.head a /= Text.head b then
1 + naiveRec (Text.tail a) (Text.tail b)
else
naiveRec (Text.tail a) (Text.tail b)This, most simple version of an implementation with explicit recursion is probably very readable. We could also imagine a hand-optimised version where we rely on the assumption that tail calls are more efficient.
let
go !a !b !distance =
if Text.null a then
distance
else if Text.head a /= Text.head b then
go (Text.tail a) (Text.tail b) (distance + 1)
else
go (Text.tail a) (Text.tail b) distance
in
go a b 0In this, we also get the opportunity to use bang patterns to force the iterating variables to be strict. Note that in Haskell terms, this is very low-level code. But it's still pure, functional, well-typed and all those other benefits we get form Haskell.
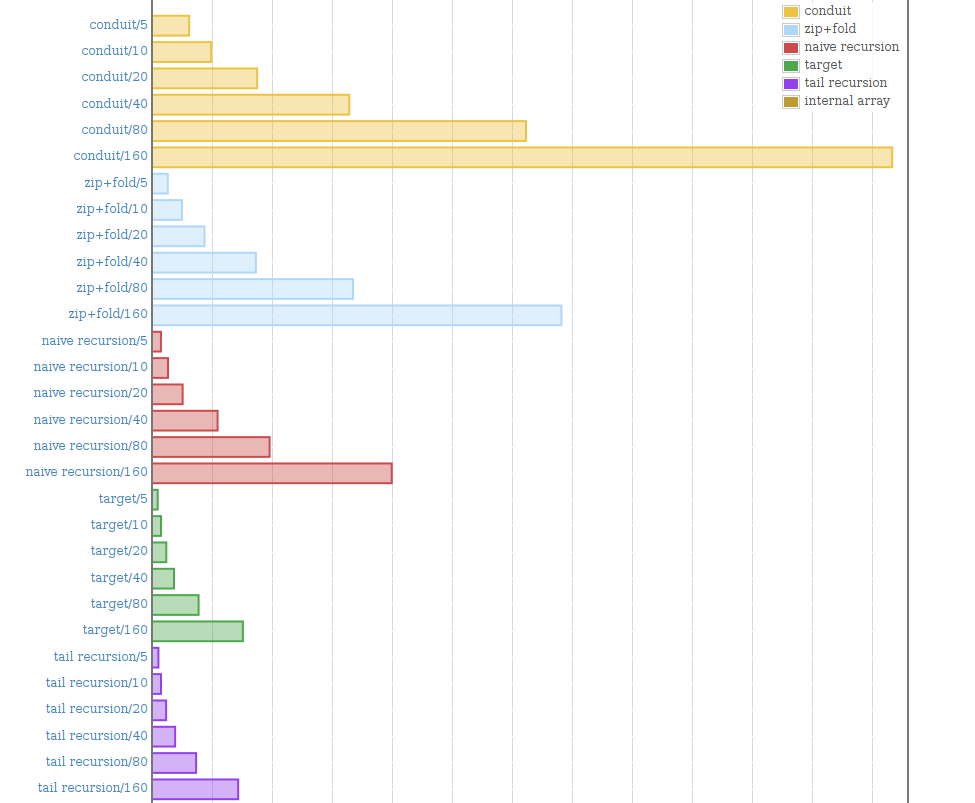
The results from these two were the ones that surprised me the most.
It appears manually converting the function to one based on strict tail calls yields a huge performance improvement. I would have thought the Haskell compiler could do this on its own, but according to these benchmarks – not so.
What's also cool is how the strict tail-recursive function performs better than the target, which in turn is pretty optimised and allegedly performs on par with C. However, looking at the two, that feels fairly obvious. They are practically equivalent in terms of semantics. The difference is that one unconses at a specific index, and the other unconses at the head and passes along a reference to the tail.
Conclusion
So, okay. This is where the real comparison stops.
By writing very straight-forward (although somewhat low-level) pure, functional Haskell code without any special trickery, you can get performance equivalent to what you'd get by calling out to a C function, which is also in the same order of magnitude as the same algorithm implemented in a program completely written in C.
Neat results!
About the Length Check
I promised I'd get into the length check, so here it is: in the text library as it currently stands, getting the length ("number of characters") in a string is an O(n) operation. Since the library stores characters UTF-16 encoded under the hood, it only knows how many 16-bit values the string is stored as, not how many characters those values represent. When you ask for the length of the string, it has to go through all 16-bit values to count how many characters they actually correspond to.
But! The hamming distance is undefined for strings of different lengths. And some of the algorithms hinge on this assumption to give the correct result. The original author first compares the length of both strings before getting into their algorithm, but as we now know, that carries an O(n) penalty.
The good thing about the explicitly recursive implementations (and the cheaty implementation below) is that the length check can be manually inlined into them. What I mean is that they can, as part of each iteration, check if either of the strings have terminated, and if they have, just not return a value. This folds two O(n) operations into just a single, ever so slightly more expensive one.
Writing Fast Haskell
Over the years, I've accumulated some intuitivistic knowledge on how to write fast Haskell code. I'll try to write some observations and general rules of thumb here.
- You want to use fast data structures and libraries. Of course. Don't use the
built in
String, for example. - You want to avoid more complicated language constructs, which are harder to convert to machine code: type classes, higher order functions, partial application, nested expressions, and so on. It's better to repeat a function call a few times in the code than to loop through a repeated list of it.
- You want to use simple language constructs, which are easy to convert to
machine code:
if,case, explicit recursion,int,letbindings, tail calls, fully saturated function calls, and so on. - You want to avoid operators and combinators when you can express the same
thing explicitly. I.e.
\x -> f x (g x)is better thanap f g. - You want laziness for things which may not be needed, and strictness for things that do.
- You want to compose functions that fuse well (i.e. easily trigger the
compilers stream fusion optimisation rules). It turns out
foldl'is not one of those. - And here's a surprise: I would assume that calling
uncurry fwould be generate slower code than\(x, y) -> f x ybut it turns out it doesn't. I haven't tried to figure out why, but I think it may be because one of the ghc authors is a huge fan of theuncurryfunction and thinks its important that it should be fast.
Internal Array Comparison
Could we do even better, though?
let
Text arra ofa lena = a
Text arrb ofb lenb = b
loop !i !distance =
if i < lena then
if TA.unsafeIndex arra (ofa + i) /= TA.unsafeIndex arrb (ofb + i) then
loop (i + 1) (distance + 1)
else
loop (i + 1) distance
else
distance
in
loop 0 0As it turns out, yes. Ish. We can unpack the text value into its primitive, hidden, internal components:
- a pointer to an array,
- an index into that array, and
- a length representing the number of words (16-bit values) to read
With these, we can count in how many places the 16-bit values differ.
This is not a correct solution for the problem, because not all characters can be represented by a single 16-bit value, so if one string contains a character that needs two 16-bit values, the offsets will be wrong for the remainder of the computation.
It's also not good because it relies on the internal structure of the text object, which counts as a hidden implementation detail and may change without warning in future versions of the library.
But it's fast.

Sorry, wrong image.
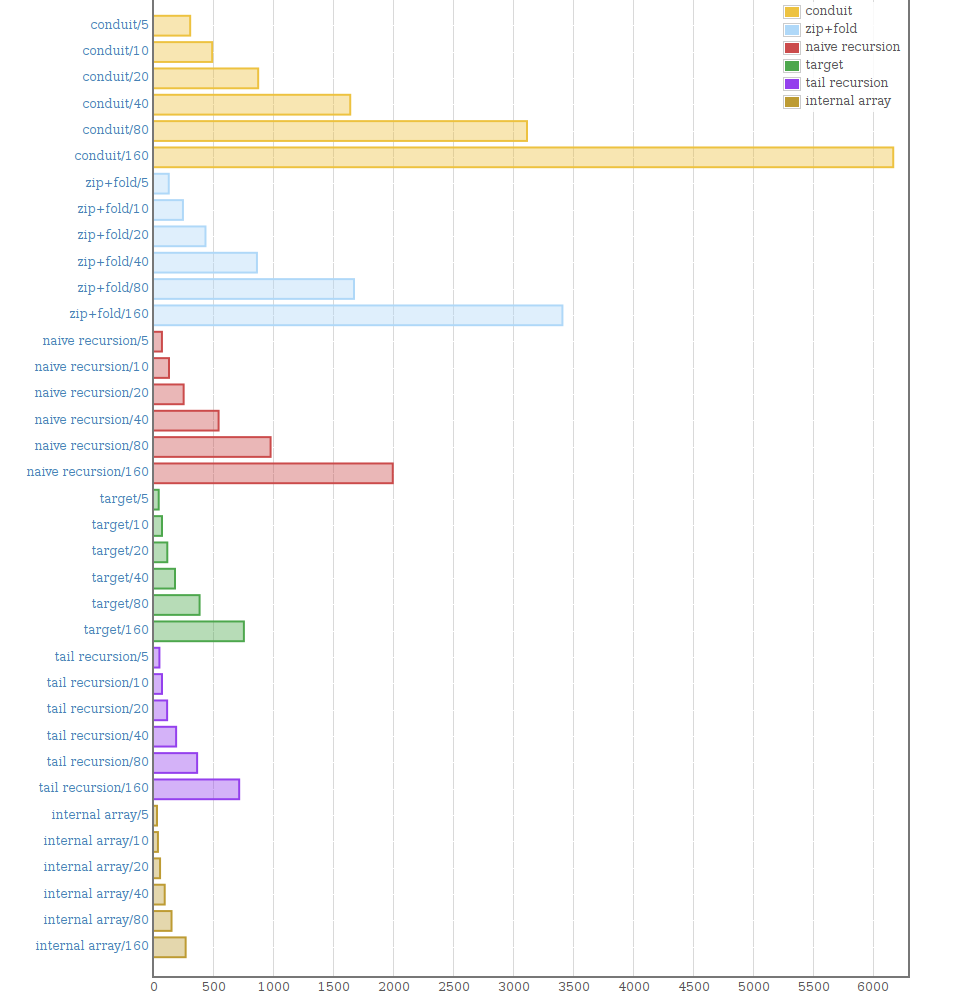
As we can see, this runs significantly faster than the best correct version. In fact, this implementation gives you practically the same performance as the program written only in C, which is not even twice as fast. Much faster than calling out to C from Haskell. How does it do that?
It doesn't have to unpack Word16 values into
Characters every iteration. Which hints at some sort of
optimisation we can do! We could imagine comparing pairs of 16-bit words
until one of them is a surrogate pair, in which case we let the text
library deal with it, and then go back to comparing 16-bit values.
It may sound expensive to check for surrogates every iteration, but the idea is that if the string consists mostly of characters that aren't made up of surrogate pairs, the branch predictor should let the cpu thunder through the condition to the 16-bit value case anyway. And we only pay the price for surrogate pairs when we actually use surrogate pairs.
Doing so in fact yields code that performs closer to the raw 16-bit version than the otherwise fastest tail recursion implementation.
Testing and Benchmarking
Just for future reference for my own good, here's the code I used to test and benchmark these implementations.
implementations =
[ ("conduit", conduitBase)
, ("zip+fold", foldZip)
, ("naive recursion", naiveRec)
, ("target", unsafeIter)
, ("tail recursion", tailRec)
, ("internal array", countSamePrim)
]I wanted to be able to construct pairs of text values that were of equal length and had different hamming distances. The default arbitrary instances for text objects generate a huge range of characters, which means the likelyhood of having two equal characters at any index is about 0. So for the benchmarks, I settled with generating text values from six different characters.
data TextPairs = TextPairs !Int !Text !Text deriving Show
instance Arbitrary TextPairs where
arbitrary = sized $ \size -> do
ta <- vectorOf size (elements ['a'..'f'])
tb <- shuffle ta
pure (TextPairs size (pack ta) (pack tb))I ensured all implementations gave the same result by comparing the result of each function with its next neighbour in the list.
prop_working (TextPairs _ t u) =
let
fns = List.map snd implementations
in
List.and (List.zipWith (\f g -> f t u == g t u) fns (List.tail fns))
$(return [])
runTests = $quickCheckAllThe program runs all quickcheck tests and generates a bunch of texts to benchmark on.
main = do
runTests
texts <- mapM (generate . flip resize arbitrary) [5, 10, 20, 40, 80, 160]
defaultMain
[ bgroup name
[ bench (show size) (whnf (fn ta) tb)
| TextPairs size ta tb <- texts
]
| (name, fn) <- implementations
]