Root Cause Analysis? You’re Doing It Wrong
If you have arrived here, you should know this is an early draft containing mostly unedited stream-of-consciousness crap because I have found it difficult to structure this topic. My latest attempt is to split this information up into multiple separate articles.
- The first of those is about hazardous states and accidents.
- Then I performed an stpa analysis of that expensive aws DynamoDB accident.
- I’ve also argued that Cloudflare’s reporting of their expensive accident shows symptoms of root cause analysis, and what they are missing.
- There’s another article on why software never fails.
Read those instead. They’re better. If you’ve read all three of those and still long for more, you can subscribe and I’ll publish more. If you still need more, you might find some value in what’s below. But most likely not.
Table of Contents
The best book I know on accident analysis is the _cast_ Handbook1 _cast_ Handbook; Leveson; independent; 2019. Available online. It explains exactly how and why people approach accident analysis incorrectly. Unfortunately, it’s also a long read. This article is a shorter version; I hope it is still somewhat useful. Most of this article draws quite directly from the cast Handbook, so if you want more details and examples from other domains, read the book!
Summary
The summary is extremely brief and won’t teach you much, but if you want to quickly verify whether you already know what I’m about to say, check if you agree with the following statements:
- Techniques such as root cause analysis are based on simplified models of the world that lead to insufficient understanding.
- If we analyse accidents more deeply, we can get by analysing fewer accidents and still learn more.
- Just as important as preventing an accident – perhaps even more important – is limiting the negative consequences of it when it happens.
- An accident happens when a system in a hazardous state encounters unfavourable environmental conditions. We cannot control environmental conditions, so we need to prevent hazards.
- Controllers avoid hazardous states by maintaining system constraints. They do this by interacting with the system, issuing control actions and receiving feedback.
- Control actions are usually technical (e.g. automatic failover) at a low level, but social (e.g. organisational culture) at a high level, and something in between at middle levels (e.g. penetration testing).
- There is always a long list of contributing causes to any accident.
- Accident analysis never stops once it encounters human error – rather, human error serves as a good starting point for the real investigation.
- Any decision made in the past was far more complicated than it looks now.
- Following procedures is a damned-if-you-do-damned-if-you-don’t type of thing.
- Humans are flexible and can react dynamically to changing conditions. This is mostly good, but sometimes contributes to accidents.
- Systems must facilitate operators in building accurate mental models.
- Humans are fundamentally input–output boxes, strongly affected by their operations environment.
- Safety is not a failure prevention problem; it’s a dynamic control problem.
TK TK + edit a lot of the sections that follow. they are very wordy.
Introduction
The world, and the system2 Not necessarily a software system, but often in my case. we’re trying to analyse, is a complex web of causal factors that influence each other as well as the outcome. Most people ignore this complexity when trying to analyse accidents, e.g. by doing a root cause analysis. The root cause methodology pretends the world is relatively simple and that problems can be tracked down to a single, arbitrary root cause. This straightforward model of the world makes analysis easier. It also guarantees that the result is no longer useful in the real world.
A root cause methodology allows us to find a somewhat easy, convenient target to fix, fix it, and then declare victory. In contrast, with proper analysis we will find a multitude of problems, only some of which we may be able to fix. This may leave a sour taste, especially in the mouths of managers who will ask why we are wasting time finding problems we can’t fix.
However, this is also what’s nice about a more realistic model of the world: any given accident tries to teach us many lessons. Rarely did only one thing go wrong. Not listening to everything an accident is trying to tell us is a waste of a good crisis.
A thorough analysis takes time. We won’t be able to deeply analyse every accident. The upshot is that when we aim for quality over quantity, we will learn multiple lessons from each accident, and we will learn more factors that are common to multiple accidents. In other words, we analyse fewer accidents but what we learn from it can be used to prevent more accidents than a shallow analysis would allow. A shallow analysis tends to lead to only papering over symptoms.
Something people often forget is that we cannot entirely eliminate accidents from complex systems. In addition to preventing accidents, we need to design systems such that the negative impact of an accident is limited. In my experience, the more reliable systems tend to actually break more often, but their breakages are of lower severity and easier to fix.
In this article, we are talking about a specific approach to deeper accident analysis, called cast, or Causal Analysis based on Systems Theory.
Example
Before diving into more details, let’s start with an example of how not to analyse accidents.
I worked on a software system that once failed in an embarrassing way (for us – the customer was nice enough about it.) The support staff performed their root cause analysis3 Judging by the format, perhaps they attempted some sort of “five why” methodology. on the request of the customer, Lawzilla, and here’s the relevant part of their report4 I have replaced the names with ones generated by http://projects.haykranen.nl/java/.:
Dear IT Contact at Lawzilla,
Your api calls were hanging because they were trying to access the
SimpleWatcherBridgesupporting system. This system was not responding due to resource exhaustion, having run out of threads to handle further requests. The existing threads were in turn stuck in infinite loops, caused by corrupted data. The data had been corrupted due to a race condition during multi-threaded operation, which happens only rarely, and only ifPropertyVisitorAutowireMappingis enabled in combination with multi-threading. Multi-threading had been previously enabled based on your request to improve the performance of the system, andPropertyVisitorAutowireMappingwas enabled to support the latest business initiative.Thus, the root cause of this incident was turning on
PropertyVisitorAutowireMappingwhen multi-threading had already been enabled prior.The corrupted data is not critical and have been purged, with no loss of functionality for your.
We will fix the root cause by amending the system so that the settings for
PropertyVisitorAutowireMappingare considered invalid if multi-threading is enabled.After this fix is implemented, your problem is guaranteed not to recur. We apologise for any inconvenience up to this point.
Sincerely yours, Support Contact at Our Organisation
This so-called “analysis” is typical of what you get when a customer asks you to perform an analysis. Customers don’t want an actual introspective analysis; they want a pr piece where you accept blame for the problem with an apologetic tone. But let’s imagine that we actually wanted to find out what went wrong.
As you can sense already, there have been many things going wrong in this scenario, and the analysis ended up focusing on and addressing only one of them. This leads to another symptom of poor accident analysis: we stopped just as it got interesting. Why did someone turn on incompatible settings? Why was it even possible to turn on incompatible settings in the first place? These hint at organisational and methodological problems – high value targets for analysis, but not even mentioned in the analysis performed above, because someone decided that they had found the root cause and terminated analysis.
cast Example
We will jump straight into what this analysis looks like when it’s based on cast. We will talk later about how to perform a cast based analysis.
I’m no cast expert. Although I consider myself a systems thinker, I’ve only had reason to write formal cast reports a very small number of times in my life. You can probably do a better job of this than I can. But this will serve as a starting point.
Step 1: Describe System
We are investigating an accident involving the InvocationServerAttributePool
service, hich was hanging all api calls to it for almost two hours, starting
at 14:32 on January 4, 2023. This caused Lawzilla’s StrategyContextPublisher
to malfunction in a way that prevented their associates from doing their work,
costing them labour time equivalent to more than $2000. We only noticed when the
customer called us about it. Once the problem was resolved, the failed requests
were retried by the StrategyContextPublisher and had their intended effect.
We will not include the StrategyContextPublisher or any other of Lawzilla’s
systems in our analysis. Although there could be problems there worth fixing, we
do not expect them to have the proficiency to make any real improvements in that
area.
There were three high-level constraints violated during this event:
- The
InvocationServerAttributePoolshould not hang api calls. - If some api calls are hung, different api calls should not hang.
- Our on-call engineer should be notified of consistently hanging api calls within five minutes.
There was one high-level constraint that was not violated during this event:
- If a failed request is re-tried, it should be successful and have the effect intended the first time it was issued.
The relevant parts of the systems involved have the following dependency graph:
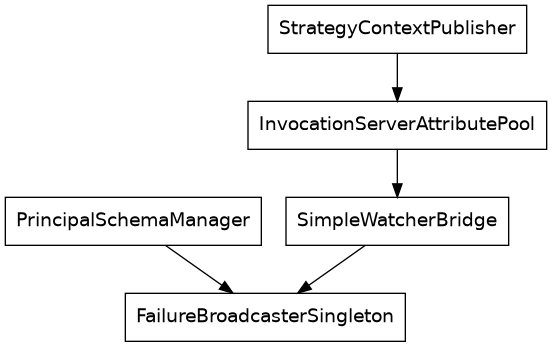
Step 2: Accident Timeline
- The
PrincipalSchemaManagerwas designed quickly to meet the demands of an early customer. It was designed to be simple and easy to implement: single-threaded and managing schemata in batches. It grew in functionality over a few years with adoption of new customers, and part of its responsibilities were spun off into a new service,FailureBroadcasterSingleton. This inherited the single-threaded design. - One developer spent a few days on their own initiative to enable
multi-threading in the
PrincipalSchemaManager, and defaulted the concurrency level to 1, to lower the risk of the change. Increasing the concurrency level can yield up to three times the processing rate. The default multi-threading setting was never changed from 1, and most customer installations kept it at 1. - A large customer desired more flexible and fine-grained control over their
principal schema management, which resulted in a two-month project to add the
PropertyVisitorAutowireMappingto thePrincipalSchemaManager, enabling streaming management of schemata, instead of just batch processing. - When Lawzilla had problems with slow processing, an sre experimented with concurrency levels and found that at a multi-threading level of 6, they had optimal performance – approximately 1.8× faster than single-threaded performance.
- Lawzilla approached us about a new business initiative, and they wanted what
we could do to support that. We informed them of the
PropertyVisitorAutowireMappingfunctionality, and they wanted to use it. It was enabled in their installation and they integrated with it. This resulted in a new class of faults that were registered with theFailureBroadcasterSingleton. - In combination with multi-threading, the new class of faults from the
PropertyVisitorAutowireMappingwere sometimes registered concurrently in theFailureBroadcasterSingleton. The concurrent registration of faults lead to incorrect counts being stored for some faults. - When the
StrategyContextPublisherrequested the operations status of the system through theInvocationServerAttributePool, theSimpleWatcherBridgeread the corrupted counts, which were used as upper bounds for a low-level iteration in theSimpleWatcherBridge, which consequently took a long time to terminate its iteration. - With the
SimpleWatcherBridgenot responding in a timely manner, theInvocationServerAttributePoolalso did not respond, and theStrategyContextPublisherretried the failing requests. - Eventually, the
InvocationServerAttributePoolhad all threads stuck in the infinite loops, and further requests of any kind were hung waiting for a thread to become available.
Step 3: Initial Questions
The timeline has provoked the following questions from the accident investigator:
- The
FailureBroadcasterSingletonwas spun off into its own service. Did this signal that it had become a more important and more frequently modified component? Why was the opportunity not seized to break free of the quick and dirty design principles of thePrincipalSchemaManager? - After the successful proof of concept of multi-threading in the
PrincipalSchemaManager, why was it not made into a real product enhancement? Why did the developer not consider the multi-threading support of collaborator services? Why was this not caught during design or code review? Did developers have insufficient understanding of how the system was pieced together? - Why was there no plan for changing the default multi-threading level given the performance improvement? Did developers suspect that there may be remaining concurrency bugs in the product? Was this concern taken seriously by management?
- Was sre_s changing concurrency levels without consulting anyone else standard practise? Did the _sre team and system developers have different ideas of the risk level of this change? Were there ever any consideration of running a cloned system with the higher concurrency level while monitoring its performance with live traffic and being able to quickly fall back to the old one?
- Why did the
SimpleWatcherBridgenot validate the data in a way that let it reject the corrupted counts, e.g. leveraging redundancies, invariants, or even statistical properties of counts over time? Given that the iteration takes a long time to run, why did it not include a hard-coded upper bound overriding the count in extreme cases? - Why did the InvocationServerAttributePool called the SimpleWatcherBridge without a timeout? Why didn’t it have a circuit breaker to prevent limitless retries of failing requests? Why didn’t it terminate old threads to ensure there’s always room for the latest request?
Step 4: Failures And Unsafe Interactions
We expect the following safety controls to be present in a well-functioning development and operations environment:
- Development time is spent on finding and fixing bugs.
- The product owner has a good understanding of a large variety of problems that can occur in software.
- There is a way for developers to get problems fixed, even if the product owner does not agree that they need to be.
- The locations and types of bugs are tracked statistically to reveal trends of neglect.
- Development improves system design.
- The development manager ensures developers improve their skill, rather than get stuck in their ruts.
- The organisation ensures developers get feedback from production, e.g. by being partly responsible for operations.
- All new development is reviewed in the design stage as well as before it is merged.
- Integration testing of new combinations of settings is performed.
- Developers can easily stand up a complete production environment for testing.
- The product owner leverages _slo_s to guide development, encompassing things like performance, availability, and change failure rate.
- When expectations are violated in the software, it has a limited effect on end
users.
- The software uses timeouts for all I/O operations, including synchronisation, to avoid getting stuck anywhere indefinitely.
- The software uses circuit breakers to avoid indefinitely retrying failing operations.
- The software dumps critical information when it encounters problems, including stack dumps and diagnostic log messages.
- The software performs validation on all ingested data ( even self-produced), and rejects all inconsistencies.
- Expectations in terms of performance and availability of collaborators are explicitly documented, and alerting is set up to notify humans when expectations are violated.
- Functionality is entered into production in a safe and reliable way.
- New functionality is introduced with safe defaults (or under feature flags).
- New functionality is tested in controlled production experiments (e.g. canary deployments).
- New functionality comes with a plan for migrating to new defaults after a fixed time (or for removing the associated feature flag.)
- Unused, or rarely used functionality is removed to reduce complexity.
- Design choices are documented in a way that is readable by an sre.
Basic Concepts
Now that we know what an analysis can look like, let’s dive into how to perform it.
An accident is any undesirable event. For the purposes of this article, it’s additionally an undesirable event that someone wishes to expend resources (time or money) on preventing in the future.5 Note that an accident does not have to be “accidental.” Sometimes you deliberately cause one accident to prevent another, much worse, one. A past team of mine once deliberately null-routed traffic to a system because the system had an unpredictable memory leak and for this system, preventing usage entirely was considered better than waiting for it to crash on its own at some inconvenient time.
A system has a goal. We create systems in order to accomplish something. Systems have a purpose.6 If you have something that looks like a system but is lacking purpose, you might think of it as an organism or something else complicated-but-not-designed-for-a-task.
In addition to a goal, a system comes with constraints. These define the boundaries of what the system is allowed to do in pursuit of its goal. A common constraint on software systems is that they’re not allowed to use unbounded resources, or they should continue to function in the absence of an internet connection. Constraints are important for accident analysis because virtually all accidents happen when a constraint (explicit or implicit) is violated or missing.
When analysing system, we can sometimes point to a subsystem that enforces these constraints, and then we call this subsystem a controller. The controller sends control actions to the system and receives feedback from it, with the purpose of keeping the system within desired constraints. Control is to be interpreted very broadly: redundant components with automatic failover can be modeled as a control action, much like training programmes are a control action. At a low level, control might be technical. At higher levels, control is almost always a social function.
Another important concept is that of a hazardous condition, or simply hazard. An accident occurs from the combination of unfavourable environmental conditions, and a hazardous (vulnerable) system condition. For example, a corrupted backup represents a hazard in the backup system. It’s not guaranteed to lead to an accident, but if the main system fails and the backup needs to be restored, an accident will occur. The reason it’s important for accident analysis to talk about hazards is that we cannot control environmental conditions. Sometimes they will be favourable, and sometimes unfavourable. If we are to mitigate the ill effects of accidents, we must prevent the system from entering hazardous states, and try to reduce the impact of the accident when it does occur.
Difficulties
There are many difficulties with performing a proper accident analysis. We’ll look at some people don’t talk so much about. In particular, I will not write a section on blame. I think my readership knows a lot about psychological safety and blame-free investigations, and there’s no point in me beating that horse.
Hindsight Bias
Whenever something complex happens, humans have a strong tendency to invent simplified explanations after the fact. It can sound something like7 If you can’t tell, I’m enjoying War and Peace at the moment.,
Well, obviously Napoleon’s troops were going to starve and freeze to death in the the winter 1812 on the roads to Moscow. Nobody starts a campaign to reach the capital of Russia in the summer for precisely this reason. The Russians knew this, so they parted their army in two, let the French army through and waited for their lines to stretch thin, and then went on a counter-attack.
But had we asked Russians in late 1811 what one should do to repel the French forces, would the above have emerged as a clear consensus? No. One could imagine most Russians would think the correct response is to meet Napoleon in battle as soon as possible to limit the extent of his occupation.8 And indeed this was what was attempted – and Napoleon split the Russian army into two, lowering their force concentration, making a counter-attack harder. The narrative of the intentional winter pincer is a convenient, simplified explanation constructed after the fact. Things often look clear after the fact.
If only we had looked at the right signals, we would have been able to predict the 2008 great financial crisis a year in advance.9 I know this because some people did, and they profited greatly off of it. The problem is that before the thing happens, you don’t know what the right signals are. Most of the time when you think you are looking at the right signals, you are not.
Thus any accident analysis that rests on phrases like “the operator must” or “the operator didn’t” is almost always flawed. Those phrases are usually indications e analysis is based on after-the-fact clarity. They are based on evidence collected after the accident. The operators didn’t have the luxury of relying on that.
This is a known human cognitive bias, meaning you and I suffer from it too. We can’t not – but we can be mindful of it and open to alternative interpretations of the course of events.
Common circumstances missing from accident reports are:
- Pressures to cut costs or work quicker,
- Competing requests for colleagues,
- Unnecessarily complicated systems,
- Broken tools,
- Biological needs (e.g. sleep or hunger),
- Cumbersome enforced processes,
- Fear of being consequences of doing something out of the ordinary, and
- Shame of feeling in over one’s head.
Of course, there are many more and with a careful blame-free investigation you might find out what they are.
Mental Models of the System
Humans are amazingly adaptable and dynamic components in a system. They form and continuously update a mental model of what the system is like at any given point, based on their experiences interacting with it. This model allows humans to improvise extremely effective responses to unforeseen problems – but the model can also contribute to an accident when it’s drifted out of correspondence with the actual system.
Note that operators aren’t the only humans who model the system. The designers of the system also have a model of it. The designer model frequently does not match the state of the real system, for a variety of reasons10 Discrepancies can enter as early as when the system is constructed, but often enough designers think of the system when it’s running as intended, not when it’s started up incorrectly, loaded an old version of the config, and is used for something completely different than the designer had in mind.. This can cause incorrectness in things like training manuals, standard procedures, etc. This is why “if the operator just followed the steps in their training all problems would go away” is not true – the designer’s model is often different from the real system to the point where operators frequently have to adapt trained procedures to reality in order to get any work done at all.11 This is one of the reasons it’s important that designers work with the system in operator capacity (“dogfooding”). That allows the designers to update their mental model to more closely match the real system.
All of this to say: the mental models formed by the operators are often blamed for causing problems. We tend to forget they are almost always preventing problems and making the system more efficient, and only rarely causing problems. They’re an extremely versatile and powerful tool, which must be used to full capacity to improve system safety. Systems must be designed to help the operator build accurate mental models.12 This can be done by providing easily interpreted feedback as to the state of the system, the outcome of actions, and so on.
Any solution that amounts to overruling the mental models used by operators (e.g. an enforced procedure to accomplish something) has to be considered very carefully. Sometimes these enforced processes are the things causing accidents, by robbing operators of the freedom to prevent a problem. Sometimes designers assume that “since there is an enforced process, the operator doesn’t need to understand what happens” which causes even more accidents. Even when they don’t, they end up creating organisational scar tissue and eventually it’s impossible to live up to all of them. 13 Please note that this is different from the operators codifying their current knowledge in a living standard work document.
Human Error
The basic idea one should carry about human error is that something else made the human do it. This might seem unfair – is the human never to blame for anything? Not when analysing accidents. There are two reasons for this:
- Humans will always make mistakes. We can’t design the system as if it is only going to be operated by a human that never makes mistakes. We need to account for mistakes in the design, which means figuring out which part of the design contributed to the mistake.
- If we intend to find a human at fault, we will have a much harder time uncovering the truth during the investigation. We are okay with blaming non-human systems because they don’t feel shame or fear of retribution.
In many ways, it is helpful to think of humans as complex input–output systems. However a human reacts in any situation is based on past experiences and what the environment indicated to the human. It doesn’t matter which person was in that seat – imagine that any person with the same experiences would have reacted the same way.
This means human error is never the end of the investigation. Once we encounter human error, that’s when the interesting part of the investigation begins! What made the human do something that after the fact clearly looks wrong? Wouldn’t it be nice to find out?
Causality Models
An accident analysis is – whether you know it or not – based on a causality model, an idea of how and why whatever happened happened. The most common, traditional causality model is the chain of events, one thing causes another, which triggers the next, etc. The chain of events is a very deterministic and simple model: once A happens, E is bound to eventually occur. And if E hasn’t happened, A also has not. This leads to investigators excluding important contributors because they weren’t directly involved in this specific accident.
Another common model is that of swiss cheese. It claims that we install protective layers to prevent accidents, but these layers have holes. If we are unlucky, the holes in all layers might align, which means there’s an unprocted area. The swiss cheese model shares some problems with chain of events, namely that it focuses primarily on failure events and their prevention. We can do better than that. We believe that operating a system safely requires dynamic adjustment of continuuos system characteristics.
System-theoretic Causality
Traditional approaches to safety of systems involves decomposing the system into its constitutent parts, and then analysing each part on its own for component reliability, viewing it as through a snapshot in time. This works for very simple systems, but produces distorted results for complex systems, since much of what’s interesting in complex systems happens (a) in the interactions between components, and (b) over time.
Systems theory, then, looks at the whole system. Complex systems have non-obvious couplings between components and feedback cycles that cause time-varying behaviour. We must account for this in our analysis to get useable results.
Of particular importance are emergent properties. A car does not have a component called “transportation” bolted onto the frame – transportation emerges from the interaction of components like engine, fuel, air, gearbox, wheels, etc. Traditional analysis misses emergent properties completely.
As mentioned in the initial glossary, important concepts here are those of constraints and controllers. The constraints of a system are the behavioural boundaries it must respect – e.g. a car should not go faster than the speed limit on the road it’s on. The controller is outside the system and enforces these constraints by issuing control actions and receiving feedback from the system. In our example, the driver controls the speed of the car by accelerator, brake, and gear choice. The feedback the driver uses is the speed indication on the panel in the car.
Note that (at least in older cars, the ones I’m used to) there is no single system component that determines the speed of the car14 Maybe there is some sort of governor on the engine speed to prevent damage, but I don’t know because it’s not used in normal operation, as far as I know.; the speed is an emergent property. This is why the conroller must exist outside of the system. This also means accurate feedback is critical for safe operation. If the speedometer lies, the human will issue undesirable control actions.
cast Analysis
It’s important to note that during a cast analysis, a lot of questions are generated. We can rarely answer them all on our own. Analysis involves talking to a lot of people. Ideally, by the end of the analysis, we can either answer all questions or at least determine that the remaining questions are unanswerable.
The cast Handbook uses a slightly different set of steps, but notes that it’s not a strict, formal procedure. I use the steps below becuase I’ve personally found it easier to communicate this way with my colleagues.
Some of the descriptions of these steps might be confusing. Hopefully, once you get down to the example, it will be more clear what I mean.
Step 1: Describe System
TK note about job-to-be done: 15 Note the focus on the job-to-be-done here and in the description of the constraints below. The system hung api calls. We specifically do not go in and explain the problem in terms of conflicting settings or subsystems that failed. This initial step is intentionally a very zoomed-out view.
First we try to get a grip on what the system we’re analysing really is. We establish the boundaries of the analysis – what is out of scope for the investigation, and why?
Then we look at what hazard occurred.16 Remember, a hazard makes an accident possible, but it doesn’t, on its own, guarantee one. This means we can analyse near misses just like we do full-blown accidents. In other words, we find out what state the system was in that prevented it from functioning the way it was supposed to.
In this step, it’s important that we focus on the job-to-be-done perspective. An outside viewer of the system expected it to do one thing, but it did something different. What was that different thing? It is tempting here to jump straight into explanations and start the analysis with some component failure or human error – resist! Focus on the job-to-be-done. The reason we don’t want to jump into explanations is that when we do that, we tend to prematurely prune large parts of the search space. We will miss out on important explanations.
Once we know what hazard(s) occurred, we can think of which constraints must have been violated to allow those hazards to occur. There are three types of constraints worth considering separately:
- What problem needed to be prevented in the first place? (Sometimes this just echoes the hazard.)
- What can be done to reduce the immediate impact of the problem if it occurs?
- What can be done to help patch things over and return to normal operation as quickly as possible after the problem has occurred?
Step 2: Accident Timeline
Once we know what system we are looking at, what the accident was, and what measures should be in place to prevent that accident from occurring, we can write a brief timeline of important events leading up to the accident.
Given the negative treatment of chain of events-type reasoning above, you may be surprised about this step. There’s an important difference: this timeline is not meant to explain anything. This timeline is only here to jog people’s memory and get them back into the action leading up to the incident, as well as make it clear in what direction to start asking questions.
This also means constructing the timeline is a very low-pressure activity. It doesn’t have to be complete, and there’s no right or wrong in terms of which events to include. The important thing is to just get started with something.
Step 4: Failures and Unsafe Interactions
how can we design these systems so they avoid the accident that happened? what were the missing best practises in each area?
Personal notes
how does this system work?
SCP = StrategyContextPublisher
ISAP = InvocationServerAttributePool
SWB = SimpleWatcherBridge
FBS = FailureBroadcasterSingleton
PSM = PrincipalSchemaManager
PVAM = PropertyVisitorAutowireMapping
SCP ----> ISAP
| ----> SWB -- { infinite loops, corrupted data }
| ----> FailureBroadcasterSingleton
PSM -- { multi-threading & PVAM }
| ----> FailureBroadcasterSingleton
Later
things to consider:
- procedures
- attitudes and motivations of everyone involved
- relationships with management
- quality control
- documentation
- interfaces
- design/operation communication
- political considurations
- resources
how to do the analysis example properly:
- system should not hang on third-party collaborators
more inspo: https://github.com/joelparkerhenderson/causal-analysis-based-on-system-theory