Software Never Fails
One of the most confusing ideas in system-theoretic accident analysis is that software never fails. Taking this perspective helps us design more robust software.
The brief reason we can say software never fails is that software always does precisely what we told it to do. The outcome may be undesirable, and it may be unexpected, but the software itself never deviates from the instructions it was compiled into.
If software contains a bug, it’s not something it did to itself. All bugs we suffer because we put them in there. For every 10–100 lines of code you write, you add a bug.1 This number comes from various studies on fault injection rate I read a while ago. Sloppier code (such as you find in web development, enterprise software, etc.) will be closer to the lower end of the range, and important code (automotive, space, weaponry, etc.) will be closer to the upper end of the range. If you disagree with the number, you need to propose an alternative hypothesis, not just complain. Here’s one way you could do it. First find the fault discovery rate in your organisation by knowingly but secretly injecting some bugs into code you write and seeing what proportion of them are caught by reviewers. After you have done that, for the next 10,000 lines of code reviewed, count how many bugs are found in code review, specifically. Divide that by the fault discovery rate, and you get the total number of bugs introduced in those 10,000 lines of code. Do some statistical magic to combine the various sources of variance, and the one-per-10 or one-per-100 lines of code fault injection rate will probably fall in your confidence interval.
The normal response to this is to shrug it off. We’re going to do something controversial: we’re going to take the perspective that the software hasn’t failed – it did what we designed it to do.
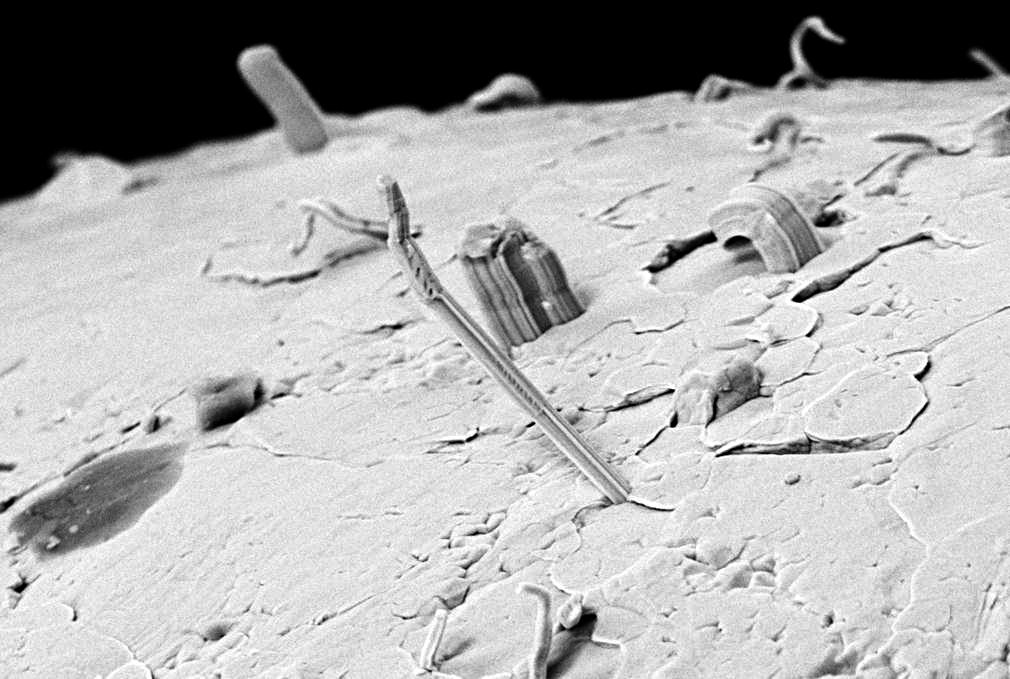
Figure 1: Tin whisker. Source: esa. Redistributed under the terms of CC BY-SA 3.0 IGO
Sure, hardware can fail – there can be tin whiskers and brownouts and cosmic ray bit flips in memory – but that’s not the software failing. The software is pure design. A design can contain errors, but it cannot fail. The ink on the paper can degrade with exposure to environment, but this is again the hardware representation failing, not the design itself.
This perspective helps us because it forces us to adopt methods of analysis that reveal potential accidents triggered by nothing at all failing – an extremely common problem in software systems.
To understand this, we first need to know what a failure is.
Failures are events, design errors are constant
A failure is the event that occurs when a component first does what we designed it to, then something happens, and then the component no longer does what it was designed to do. The failure is the event that caused the component to go from working to failed.
- A fan blade wearing out and breaking off is a failure, because the fan started out holding together and it was indeed designed to stay in one piece, but now it is in two pieces, and no longer performs its job.2 The asymmetry probably also degrades remaining blades faster.
- A capacitor that starts bulging is a failure, because the capacitor was designed to store a particular level of charge at its operating voltage, but now is not able to do that.
- A microchip developing a tin whisker that leads to a short circuit is a failure, because the chip worked before the whisker made contact, and then doesn’t do the right thing afterwards.
- Memory corruption due to cosmic rays is a failure, because the chip was designed to hold a bit as long as it is powered, but then it holds the wrong bit.3 This shows that not all failures are due to wear-and-tear. Some are so-called random failures that can happen at any point in the component’s lifetime.
The consequences of failure can be reduced with redundancy. This is why we have redundant network links and power supplies in our data centres, why error-correcting ram stores data redundantly, and why we have a passive standby database.4 Note that data corruption will be replicated to the standby database. The standby only protects against component failures, not programming errors.
In contrast to failures, an error in a design is a constant fact of that design, rather than an event. Even if the design flaw is revealed in some catastrophic loss, the loss did not cause the design to go from good to flawed – it was flawed all along.
Software, being pure design-stuff, does not wear out over time, nor change itself randomly into a non-working configuration. Whenever software does not work, that error was always in the design from the first minute of deployment, even if it took some time for the error to be revealed.
What people mean by software failure
To ensure I’m not cherry-picking software accidents to support my argument, I asked an llm to list ten high-profile software accidents in recent history.5 In each of these cases, many things went wrong, so I also listed all software problems I found during a quick skim of their Wikipedia pages and used a random number generator to select one software problem to focus on for each. In each of these cases, you will find people claiming that “the software failed”. I will argue that in all cases, the software performed exactly as designed.
In some cases, explicitly requested features contributed to the loss. In other cases, the software was designed with emergent features nobody wanted, and those features contributed to the loss. Either way, it is always a feature designed into the software that contributes to the loss.
Therac-25 (1985–1987): “Medical radiation machine software bug killed 3 patients, injured 3 others with massive overdoses.”
The race condition in the software didn’t suddenly appear as a random failure. It was consistently reproducible. The Therac-25 had been designed with an emergent feature: the fast-typing operator could enable a high-power, focused electron beam mode. This is an undesirable feature when there is a patient on the other side, but it was not a random failure – it was an emergent functionality of the design. It was built into the Therac-25 and could reliably be used intentionally, and unfortunately also accidentally.
Ariane 5 rocket (1996): “Integer overflow error caused $370 million rocket to explode 37 seconds after launch.”
The nozzle control software was designed to interpret any signal from the intertial reference systems as a navigation signal, so when the irs module started outputting a diagnostic bit pattern, the nozzles were deflected according to it and the rocket attitude became unfavourable. The nozzle control software did not experience a random failure; it did exactly what it was programmed to do. The rocket was designed with an emergent feature: when the irs is shut down, lose attitude control. This is not a desirable feature, but it was there in the design all along.
Mars Climate Orbiter (1999): “Unit conversion error caused $327 million spacecraft to burn up.”
Against documented suggestions, one module got implemented to use pounds as the unit of force, whereas the rest of the spacecraft used newtons. There was no conversion step, so impulse numbers expressed in pound-seconds got interpreted as newton-seconds. This is not a random failure, nor the result of wear. There was no event where the module went from working to broken during spacecraft operation. It was broken from the start, it just wasn’t revealed until it needed to be inserted into Mars orbit.
Toyota unintended acceleration (2009–2010): “Software bugs caused sudden acceleration, recalled 9 million vehicles.”
The watchdog that resets the electronic throttle control cpu if something on it misbehaves was designed such that it would be unable to detect if the task that manages throttle angle calculation crashes. When that task has crashed, the car believes the throttle is held at some angle it is not. There is speculation there may have been a hardware failure involved in the crash of the task, but the software did exactly what it was designed to do: if the task crashes, assume fixed throttle control angle. Terrible feature? Sure. Design error? Yuppers. But not a software failure.
Knight Capital (2012): “Trading algorithm glitch lost $440 million in 45 minutes, nearly bankrupted the company.”
A feature flag was toggled on by an operator who did not know one of the servers gated old code behind that feature flag. The old code executed the trades it was designed to. Nothing was broken here – everything worked exactly as designed.6 You could argue this was not the real software problem in this accident, pointing instead at the failed deployment that left old code on one of the servers. You’ll find, if you look into it, that the software involved there also did exactly what it was designed to do.
Heartbleed (2014): “OpenSSL bug exposed passwords and sensitive data across 17 % of secure web servers.”
The OpenSSL library was designed with an emergent feature where cleverly crafted heartbeat requests would allow reading server memory. Nobody wanted this feature, to be clear, but it was there all along. It was a design error, not a failure. There was no event where a running instance of OpenSSL went from working to broken. The memory reading capability was built into it from the first minute of deployment.
Equifax Breach (2017): “Unpatched Apache Struts vulnerability exposed data of 147 million people.”
The software that scanned for suspicious network activity had been designed to let traffic through unmonitored if its tls private keys expired. It’s easy to see why: halting all network traffic when keys expire can be costly for business. Sure, it is inappropriate to have the security software in passthrough mode while there is an ongoing exfiltration attack, but that doesn’t change the fact that this was a feature it was designed with, not a random failure.
Boeing 737 max mcas problems (2018–2019): “Flight control software errors contributed to two crashes, 346 deaths.”
The software did exactly what it was supposed to in response to the input it got: it assisted pilots with pointing the nose of the plane down. Did the pilots – or anyone else on the plane – want that in those situations? No. But the software did exactly what it was designed to do. It did not suddenly go from doing what it was designed to do to doing something which was not intended, so it did not fail. The angle of attack sensor failed (and there were plenty of design errors in both software and human protocols), but the software did not fail.
CrowdStrike outage (2024): “Faulty update crashed 8.5 million Windows systems globally, disrupted airlines, hospitals, banks.”
The update responsible reconfigured the Falcon® troja^H security software with a new emergent feature: if any named pipes were opened, the computer would reboot. Nobody intended for this feature to be in the software, because Windows opens named pipes in the process of booting, but it was in there none the less. It didn’t suddenly start happening; it was in that update when it left the factory.
Language model unreliability (2025): “The llm was asked for ten high-profile software-contributed losses, and it produced a list where Knight Capital featured twice, leaving me without a tenth item so I’m putting the llm itself in that spot.”
This is also not a random failure, even if at first it might seem that way. This problem is built into the architecture of the llm, and always has been. The llm is not designed to reliably follow prompts, however much their creators want to convince their prospective customers of that.7 Good, old fashioned programming is still the only way to get computers to follow instructions accurately.
That’s ten software-contributed losses you’ve probably heard of, and in none of them software failed.
When people say the software failed, they usually don’t actually mean that the software failed, but rather what we have already seen:
- The software, as intentionally designed, contributed to a loss (this is the case when an explicitly requested feature rather directly causes the loss); or
- The software was designed with emergent features we did not want (this is the case when different software components interact to create a new feature).
We have seen the phrase emergent feature a few times now, so it makes sense to clear up what it means. An emergent feature is a feature designed into the system, but which does not have a specific component responsible for it. The emergent feature emerges from the interaction between components, or the interaction of the software and its environment. Emergent features are sometimes desired, sometimes unwanted, but either way, they are designed into the software just as much as explicit features. The reason we have to think about emergent features differently is that traditional analysis methods – which decompose the system into components – tend to miss them.8 When the system is taken out of context and/or taken apart into separate components, the interactions that make up emergent features disappear.
Traditional safety engineering focuses on failures
Traditional safety engineering, i.e. how most of us try to build robust things, focuses on failures. It answers questions such as
- How long can this ball bearing run for before failing?
- In which ways can this valve fail? Can it be stuck closed?
- What happens to the reaction if the cooling circulation fails?
These are obviously related to safety, because if the ball bearing breaks, the pump will stop. If the valve gets stuck closed, circulation stops. If the cooling circulation fails, the pressure and temperature in the reaction chamber will go up. These are simple cause-and-effect relationships and we love them.
We’re also really good at dealing with them. We’re good at modeling component reliability9 Run tests, discover component failure distributions as a function of time, then compute joint probabilities of component failures accounting for conditional failures., building reliable components that do not fail10 Testing, materials science, etc. lets us build things like jet engines that virtually don’t fail. That’s why we can allow twin-engine jets to cross vast oceans these days. If – against all odds – one engine dies and the plane has to spend hours going to the alternate on just one remaining engine, we’re that sure the second engine also won’t quit., and also at addressing problems that occur when components fail11 As we have already seen, failures tend to be somewhat independent so redundancy is incredibly efficient at dealing with component failure: if we multiply two small probabilities we get a teensy tiny probability..
Traditional component failure-based analysis might sound something like
We are doing a failure analysis of our database system. There are four things that can fail in it:
- The computer the database runs on can fail (due to components inside it failing). This has an annual failure rate of 6 %.
- The power supply in the data centre can fail. This has an annual failure rate of 1 %.
- The network connection between the database and the application can fail. This has an annual failure rate of 9 %.
- The database software itself can encounter a failure that causes it to fill up the disk space with logs. This has an annual failure rate of 4 %.
The total failure rate of the database system is 20 % – a failure once every five years. This is too high for our stakeholders, so we will add a passive backup database server in a different data centre that takes over in case of failure. The probability of two of these database servers failing at the same time is 0.2×0.2 = 4 % annually, i.e. once every 25 years. This is acceptable to our stakeholders.
There are at least three problems with this analysis, though. First off, if one of the databases start to fill up with logs, it seems plausible that the other might also be exposed to the same erroneous commands and do the same thing. Thus their failures aren’t totally independent, and the 4 % figure is too low.
Second, if the database software contains an emergent feature where it fills up the disk space with logs, we don’t have to treat that as a random failure. We can handle that by figuring out under which conditions it is triggered and then working on avoiding those conditions rather than accepting it as a random failure event. We can do this because software never fails; it always does exactly what we told it to.
But the biggest problem with the analysis is that it doesn’t account for interaction problems between the two replicae. Are there conditions in which the replication process itself can make the database unavailable? Could both instances think they’re primaries and accept writes, only to later connect and discover the discrepancies, or will the system degrade into a read-only mode when the instances cannot connect to each other? The analysis completely ignores these interaction problems when it says the total failure rate of two 20 % databases is 4 %.
Traditional safety engineering focuses on the wrong thing
The problem we’re solving with safety engineering is avoiding losses. Traditional safety engineering avoids losses by looking at component failures. This seems sensible, because component failure can lead to loss, although components can also fail without loss – this is common when there is redundancy in place already. Thus we can say two things about analysis focused on failure:
- A component failure may contribute to a loss, but
- A component failure does not necessarily lead to a loss.
It’s easy to think that by focusing on failures we are, then, over-designing, i.e. covering more ground than we strictly have to. This would be a good thing when it comes to building robust systems! But that’s not really what we happens. It turns out we are focusing on the wrong thing.
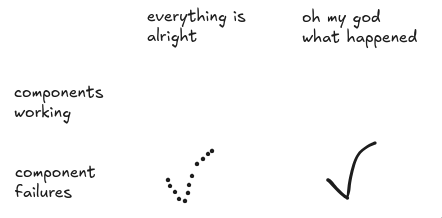
Traditional component failure-based analysis comfortably handles the case where components fail and the situation goes bad (solid checkmark). It also handles the case where components fail and the situation is fine (dotted checkmark). It gets there by asking questions about failures first, and looking for which of them cause losses later.
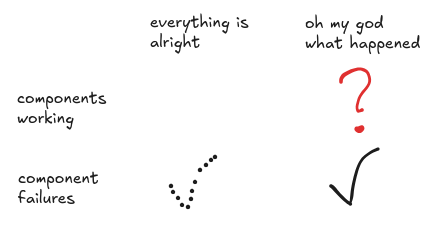
What about that quadrant where no component has failed, yet things are terrible? The traditionalists say that can never happen, but we have just seen it happen in ten high-profile software accidents. The software didn’t fail. Software is design-stuff. It doesn’t fail ever. But it sure can contribute to a loss, even when it works perfectly as designed.
The replication configuration in the database analysis above, despite working exactly as intended, could interact unfavourably with our system12 Think race conditions, split brain scenarios, replicae turning read-only, slow write confirmation triggering timeouts, etc., and lead to losses even when the database has not failed. This isn’t at all reflected by that 4 % probability which only concerned failure events. This is a loss that happens in some of the other 96 % of the time when the database works as intended.
There is a whole category of issues that can contribute to expensive losses that are entirely ignored by traditional methods that focus on failure. These exist in any complex system, but they are particularly prevalent in software systems.
We need methods better than traditional failure-based analysis to solve these issues. This is where system-theoretic methods like stpa step in. If you agree, you might enjoy articles like the introduction to hazardous states and accidents, or maybe the stpa analysis of the aws DynamoDB outage.
Think of wetware as software
As a final point, I want to mention that it’s useful to think of humans – wetware – the way we think of software. Sure, the hardware in a human can fail (lungs fill up with fluid, heart enters atrial fibrillation, brain haemorrhage, etc.) but the decisions humans make are functions of the their training and environment. Importantly, human decisions are not random.
Some of you may have had trouble accepting that software does not behave randomly. A lot of you will have trouble accepting that humans don’t behave randomly. Remember the context in which you read this: building robust systems.
If we want to build robust systems in which humans play a part, we cannot write off human decisions as random. We must investigate what made the human act that way because that’s the only way we can improve system robustness. I’m not making a philosophical statement by saying human behaviour isn’t random – it’s a practical standpoint for the purpose of safety engineering. Human decision-making never fails. Instead, human error is a symptom of a system that needs to be redesigned.
Nobody stands before a choice where one action is labeled “correct” and the other “mistake” and choose to perform the mistake. All mistakes look equally or more correct to the person at the time, for whatever reason. If we build a system which does not tolerate human mistakes, then whose fault is it really when it blows up?
It might seem like a good idea to model human behaviour as random and treat it statistically (build in failsafes and automation to catch bad human behaviour) but human factors research has repeatedly shown that’s not the way to integrate humans in a system. It doesn’t work. Humans are brought into the system when it’s too complex to automate. We rely on the human ability to handle complexity, but then we need to give the human the best possible conditions in order to achieve robustness.
So instead of modelling humans statistically, we have to investigate how humans make decisions and adapt the system to improve the process of collaboration between man and machine. I could say a lot more about human error, but that’d be a separate article. In the mean time, you may enjoy what I learned from the recent Cloudflare outage.